Natural Language Querying
Making open knowledge findable and accessible for SoilWise users
Functionality
The aplication of Natural Language Querying (NLQ) for SoilWise and the integration into the SoilWise repository is currently still in the research phase. No implementations are yet an integrated part of the SWR delivery, in line with the plan for the first development iteration.
Ongoing Developments
A strategy for development and implementation of NLQ to support SoilWise users is currently being developed. It considers various ways to make knowledge available through NLQ, possibly including options to migrate to different "levels" of complexity and innovation.
Such a "leveled approach" could start from leveraging existing/proven search technology (e.g. the Apache Solr open source search engine), and gradually combining this with new developments in NLP (such as transformer based language models) to make harvested knowledge metadata and harmonized knowledge graphs accessible to SoilWise users.
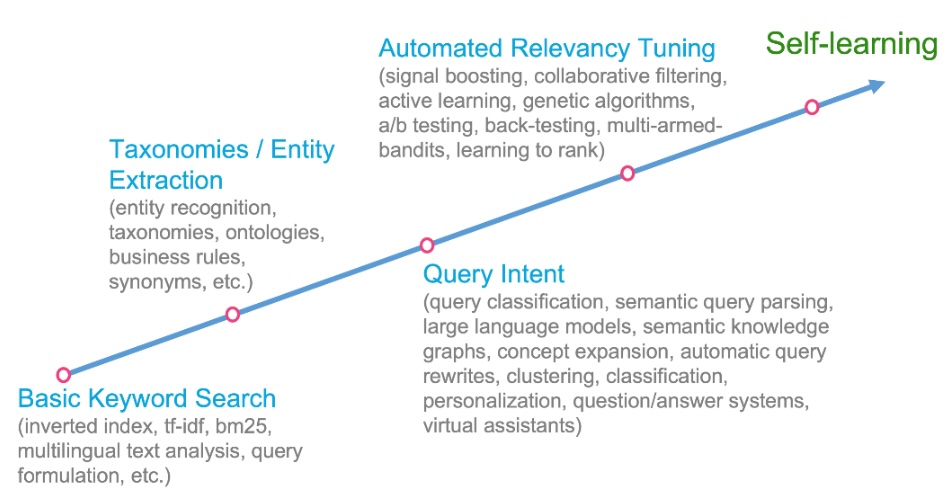
Typical general steps towards an AI-powered self-learning search system, are listed below from less to more complex. Note that to fully benefit from later steps it will be necessary to process knowledge (documents) themselves ("look inside the documents") instead of only working with the metadata about them.
- basic keyword based search (tf-idf4, bm255)
- use of taxonomies and entity extraction
- understanding query intent (semantic query parsing, semantic knowledge graphs, virtual assistants)
- automated relevance tuning (signals boosting, collaborative filtering, learning to rank)
- Self-learning search system (full feedback loop using all user and content data)
Core topics are:
- LLM1 based (semantic) KG generation from unstructured content (leveraging existing search technology)
- chatbot - Natural Language Interface (using advanced NLP2 methodologies, such as LLMs)
- LLM operationalisation (RAG3 ingestion pipeline(s), generation pipeline, embedding store, models)
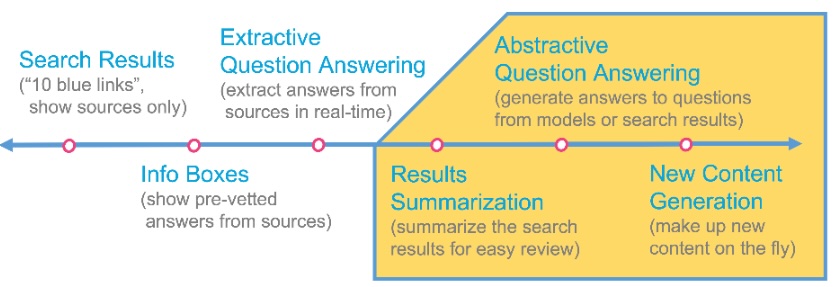
The final aim is towards extractive question answering (extract answers from sources in real-time), result summarization (summarize search results for easy review), and abstractive question answering (generate answers to questions from search results). Not all these aims might be achievable within the project though. Later steps (marked in yellow in the following image) depend more on the use of complex language models.
One step towards personalisation could be the use of (user) signals boosting and collaborative filtering. But this would require tracking and logging (user) actions.
A seperate development could be a chatbot based on selected key soil knowledge documents ingested into a vector database (as a fixed resource), or even a fine-tuned LLM that is more soil science specific than a plain foundation LLM.
Optionally the functionality can be extended from text processing to also include multi-modal data such as photos (e.g. of soil profiles). Effort needed for this has to be carefully considered.
Along the way natural language processing (NLP) methods and approaches can (and are) also be applied for various metadata handling and augmentation.
Foreseen technology
- (Semantic) search engine, e.g. Apache Solr or Elasticsearch
- Graph database (if needed)
- (Scalable) vector database (if needed)
- Java and/or Python based NLP libraries, e.g. OpenNLP, spaCy
- Small to large foundation LLMs
- LLM development framework (such as langChain or LlamaIndex)
- Frontend toolkit
- LLM deployment and/or hosted API access
- Authentication and authorisation layer
- Computation and storage infrastructure
- Hardware acceleration, e.g. GPU (if needed)
-
Large Language Model. Typically a deep learning model based on the transformer architecture that has been trained on vast amounts of text data, usually from known collections scraped from the Internet. ↩
-
Natural Language Processing. An interdisciplinary subfield of computer science and artificial intelligence, primarily concerned with providing computers with the ability to process data encoded in natural language. It is closely related to information retrieval, knowledge representation and computational linguistics. ↩
-
Retrieval Augmented Generation. A framework for retrieving facts from an external knowledge base to ground large language models on the most accurate, up-to-date information and enhancing the (pre)trained parameteric (semantic) knowledge with non-parameteric knowledge to avoid hallucinations and get better responses. ↩
-
tf-idf. Term Frequency - Inverse Document Frequency, a statistical method in NLP and information retrieval that measures how important a term is within a document relative to a collection of documents (called a corpus). ↩
-
bm25. Okapi Best Match 25, a well-known ranking function used by search engines to estimate the relevance of documents to a given search query. It is based on tf-idf, but considered an improvement and adding some tunable parameters. ↩